本文介绍如何使用Lindorm AI引擎搭建私域数据知识问答AIGC业务。
背景信息
目前,围绕大语言模型LLM(Large Language Model)构建私域数据知识问答业务成为普遍需求。构建私域数据知识问答业务的目的是让基于公共语料库训练的LLM,能够结合专属知识库中的知识进行知识问答,从而应用到企业内部智能工单答疑等业务中。
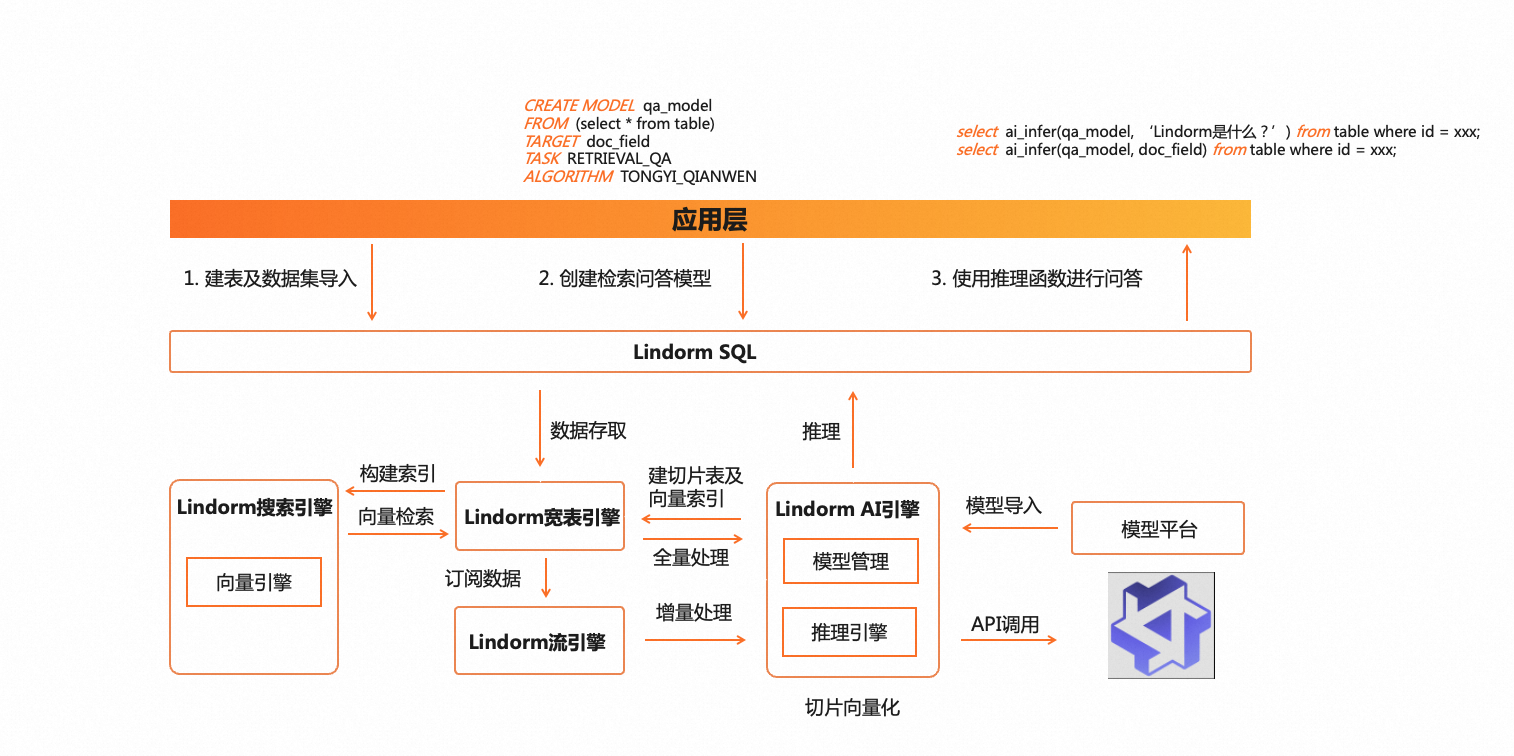
现有私域数据知识问答解决方案有两种实现方式,一种使用基础LLM在专属数据集上进行微调(FineTune),另一种利用向量检索,对用户的原始Prompt在用户数据集上进行向量检索,将检索出来的相关文档作为原始Prompt的上下文补充,让LLM在上下文中回答。其中,基于FineTune的解决方案存在成本高,时效性差的问题,现在更流行的是基于第二种“基于向量检索 + Prompt Engineering”的解决方案。在这个方案下,用户需要对原始文档进行切片,以保证不会超出LLM的token 限制并获得更好的检索效果,同时还需要对切片或问题进行Embedding提取向量,这通常可以通过调用LLM提供的Embedding API或者借助AI模型来完成。将上述流程描述成架构图,假设用户需要构建一个知识问答应用,这个应用需要实现的功能大致如下图所示,需要和包括AI推理服务、向量数据库、LLM等多个系统和服务打交道。此外,应用还需要处理文档更新的问题,在文档发生变化时,需要对应处理向量数据库中的切片及Embedding向量。

针对上述问题,云原生多模数据库 Lindorm推出一站式私域数据知识问答AIGC解决方案,结合Lindorm AI引擎和内置的向量检索能力,实现仅通过一条SQL语句就能简单构建知识问答业务的功能,简化应用开发的工作。

前提条件
已开通Lindorm AI引擎。如何开通,请参见开通指南。
宽表引擎为2.5.4.3及以上版本。如何查看或升级当前版本,请参见宽表引擎版本说明和升级小版本。
重要如果您的宽表引擎为2.5.4.3以下版本且无法进行升级,请联系 Lindorm 技术支持(钉钉号:s0s3eg3)为您升级版本。
已开通S3协议兼容功能。如何开通,请参见开通S3协议兼容功能。
已开通非结构化数据向量检索功能。如何开通,请参见非结构化数据向量检索。
模型概述
私域数据知识问答解决方案涉及多个AI模型,本示例中使用了如下模型:
- 说明
文本切片模型为默认使用的模型,目前不支持在
CREATE MODEL语句中指定。
阿里云不对第三方模型的合法性、安全性、准确性进行任何保证,阿里云不对由此引发的任何损害承担责任。
您应自觉遵守第三方模型的用户协议、使用规范和相关法律法规,并就使用第三方模型的合法性、合规性自行承担相关责任。
数据准备
连接宽表引擎。以通过Lindorm-cli连接为例,如何连接,请参见通过Lindorm-cli连接并使用宽表引擎。
创建表,用于存放知识库文档。
CREATE TABLE doc_table ( id VARCHAR, doc_field VARCHAR, PRIMARY KEY(id));在表中插入四条数据。
INSERT INTO doc_table (id,doc_field) VALUES ('1','为提升用户体验,云原生多模数据库Lindorm会不定期地发布版本,用于丰富云产品功能或修复已知缺陷。您可以参阅本文了解Lindorm宽表引擎的版本更新说明,选择在业务低峰期升级实例的宽表引擎版本。'), ('2','低成本:高压缩比,数据冷热分离,支持HDD/OSS存储。 弹性伸缩:存储计算分离架构,支持独立伸缩,自动化扩容。使用灵活:动态列,自由增减特征/标签属性;TTL,数据自动过期;多版本。低延迟:单个毫秒响应,支持双集群请求并发加速。数据通道:通过LTS(原BDS)构建Lindorm与异构计算系统的高效、易用的数据链路。高可用:主备双活容灾,请求自动容错,满足99.95% SLA。'), ('3','云原生多模数据库Lindorm时序引擎是一款高性能、低成本、稳定可靠的在线时序数据库引擎服务,提供高效读写、高压缩比存储、时序数据聚合计算等能力。时序引擎高度兼容OpenTSDB协议,采用自研的索引,数据模型,流式聚合等技术手段提供更强大的时序能力。本文从多方面介绍Lindorm时序引擎和OpenTSDB的区别,方便您了解和使用。Lindorm时序引擎默认参数采用最佳实践,无需手动调优;而OpenTSDB需要手动调优SALT、连接数、同步刷盘参数、Compaction等等。'), ('4','LindormTable提供的数据模型是一种支持数据类型的松散表结构。相比于传统关系模型,LindormTable除了支持预定义字段类型外,还可以随时动态添加列,而无需提前发起DDL变更,以适应大数据灵活多变的特点。同时,LindormTable支持全局二级索引、倒排索引,系统会自动根据查询条件选择最合适的索引,加速条件组合查询,特别适合如画像、账单场景海量数据的查询需求。');
全量检索问答
创建全量检索问答模型。
CREATE MODEL rqa_model FROM doc_table TARGET doc_field TASK RETRIEVAL_QA ALGORITHM CHATGLM_6B_INT4 SETTINGS (doc_id_column 'id');执行检索问答。
SELECT ai_infer('rqa_model', 'Lindorm是什么');返回结果:
+---------------------------------------------------------------------------------------------------------------------------------------------------+ | EXPR$0 | +---------------------------------------------------------------------------------------------------------------------------------------------------+ | Lindorm 是一款高性能、低成本、稳定可靠的在线时序数据库引擎服务。它提供高效读写、高压缩比存储、时序数据聚合计算等能力,同时高度兼容 | | OpenTSDB 协议,采用自研的索引、数据模型、流式聚合等技术手段提供更强大的时序能力。Lindorm | | 时序引擎默认参数采用最佳实践,无需手动调优,而 OpenTSDB 需要手动调优 SALT、连接数、同步刷盘参数、Compaction 等等。Lindorm | | 时序引擎提供的数据模型是一种支持数据类型的松散表结构,可以随时动态添加列,而无需提前发起 DDL 变更,以适应大数据灵活多变的特点。Lindorm | | 时序引擎支持全局二级索引、倒排索引,系统会自动根据查询条件选择最合适的索引,加速条件组合查询,特别适合如画像、账单场景海量数据的查询需求。Lindorm | | 时序引擎提供低成本、弹性伸缩、使用灵活、低延迟、数据通道、高可用等特性,支持多集群请求并发加速,满足 99.95% 的 SLA。 | +---------------------------------------------------------------------------------------------------------------------------------------------------+
增量检索问答
开通增量处理功能后,系统会自动对知识库表中新增、修改、删除的文档进行处理。
开通增量处理功能。
登录LTS并通过Pull模式创建数据订阅通道。如何创建,请参见通过Pull模式创建数据订阅通道。
重要通过Pull模式创建数据订阅通道时需指定表信息(Lindorm表名)和Kafka topic名称(主题名),且每次新建表均需要重新创建一次数据订阅通道。
创建增量检索问答模型。
CREATE MODEL rqa_model FROM doc_table TARGET doc_field TASK RETRIEVAL_QA ALGORITHM CHATGLM_6B_INT4 SETTINGS (doc_id_column 'id', incremental_train 'on', lts_topic 'rqa_xxx_topic' );其中,lts_topic参数后的
'rqa_xxx_topic'为创建数据订阅通道时设置的主题名。执行检索问答。
SELECT ai_infer('rqa_model', 'Lindorm是什么');返回结果:
+---------------------------------------------------------------------------------------------------------------------------------------------------+ | EXPR$0 | +---------------------------------------------------------------------------------------------------------------------------------------------------+ | Lindorm 是一款高性能、低成本、稳定可靠的在线时序数据库引擎服务。它提供高效读写、高压缩比存储、时序数据聚合计算等能力,同时高度兼容 | | OpenTSDB 协议,采用自研的索引、数据模型、流式聚合等技术手段提供更强大的时序能力。Lindorm | | 时序引擎默认参数采用最佳实践,无需手动调优,而 OpenTSDB 需要手动调优 SALT、连接数、同步刷盘参数、Compaction 等等。Lindorm | | 时序引擎提供的数据模型是一种支持数据类型的松散表结构,可以随时动态添加列,而无需提前发起 DDL 变更,以适应大数据灵活多变的特点。Lindorm | | 时序引擎支持全局二级索引、倒排索引,系统会自动根据查询条件选择最合适的索引,加速条件组合查询,特别适合如画像、账单场景海量数据的查询需求。Lindorm | | 时序引擎提供低成本、弹性伸缩、使用灵活、低延迟、数据通道、高可用等特性,支持多集群请求并发加速,满足 99.95% 的 SLA。 | +---------------------------------------------------------------------------------------------------------------------------------------------------+
语义检索(可选)
如果业务需要对接其他LLM ,您可以通过创建语义检索模型,使Lindorm数据库仅实现知识库语义检索(包括文档切片、向量化和向量检索)功能。
创建只处理全量文档的语义检索模型:
CREATE MODEL sr_model FROM doc_table TARGET doc_field TASK SEMANTIC_RETRIEVAL ALGORITHM TEXT2VEC_BASE_CHINESE SETTINGS (doc_id_column 'id');执行语义检索。
SELECT ai_infer('sr_model', 'Lindorm是什么');返回结果:
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | EXPR$0 | +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | ["云原生多模数据库Lindorm时序引擎是一款高性能、低成本、稳定可靠的在线时序数据库引擎服务,提供高效读写、高压缩比存储、时序数据聚合计算等能力。时序引擎高度兼容OpenTSDB协议,采用自研的索引,数据模型,流式聚合等技术手段提供更强大的时序能力。本文从多方面介绍Lindorm时序引擎和OpenTSDB的区别,方便您了解和使用。Lindorm时序引擎默认参数采用最佳实践,无需手动调优;而OpenTSDB需要手动调优SALT、连接数、同步刷盘参数、Compaction等等。","为提升用户体验,云原生多模数据库Lindorm会不定期地发布版本,用于丰富云产品功能或修复已知缺陷。您可以参阅本文了解Lindorm宽表引擎的版本更新说明,选择在业务低峰期升级实例的宽表引擎版本。","LindormTable提供的数据模型是一种支持数据类型的松散表结构。相比于传统关系模型,LindormTable除了支持预定义字段类型外,还可以随时动态添加列,而无需提前发起DDL变更,以适应大数据灵活多变的特点。同时,LindormTable支持全局二级索引、倒排索引,系统会自动根据查询条件选择最合适的索引,加速条件组合查询,特别适合如画像、账单场景海量数据的查询需求。","低成本:高压缩比,数据冷热分离,支持HDD/OSS存储。\n\t弹性伸缩:存储计算分离架构,支持独立伸缩,自动化扩容。\n\t使用灵活:动态列,自由增减特征/标签属性;TTL,数据自动过期;多版本。\n\t低延迟:单个毫秒响应,支持双集群请求并发加速。\n\t数据通道:通过LTS(原BDS)构建Lindorm与异构计算系统的高效、易用的数据链路。\n\t高可用:主备双活容灾,请求自动容错,满足99.\n\t95% | | SLA。"] | +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+(可选)语义检索模型支持通过设置可选参数score ,额外返回语义相似度。返回结果会包含格式为
[{"relatedText": xxx, "vectorScore": xxx}]的JSON字符串。SELECT ai_infer('sr_model', 'Lindorm是什么', 'score=true');返回结果:
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | EXPR$0 | +----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | [{"relatedText":"云原生多模数据库Lindorm时序引擎是一款高性能、低成本、稳定可靠的在线时序数据库引擎服务,提供高效读写、高压缩比存储、时序数据聚合计算等能力。时序引擎高度兼容OpenTSDB协议,采用自研的索引,数据模型,流式聚合等技术手段提供更强大的时序能力。本文从多方面介绍Lindorm时序引擎和OpenTSDB的区别,方便您了解和使用。Lindorm时序引擎默认参数采用最佳实践,无需手动调优;而OpenTSDB需要手动调优SALT、连接数、同步刷盘参数、Compaction等等。","vectorScore":0.68192685},{"relatedText":"为提升用户体验,云原生多模数据库Lindorm会不定期地发布版本,用于丰富云产品功能或修复已知缺陷。您可以参阅本文了解Lindorm宽表引擎的版本更新说明,选择在业务低峰期升级实例的宽表引擎版本。","vectorScore":0.6785464},{"relatedText":"LindormTable提供的数据模型是一种支持数据类型的松散表结构。相比于传统关系模型,LindormTable除了支持预定义字段类型外,还可以随时动态添加列,而无需提前发起DDL变更,以适应大数据灵活多变的特点。同时,LindormTable支持全局二级索引、倒排索引,系统会自动根据查询条件选择最合适的索引,加速条件组合查询,特别适合如画像、账单场景海量数据的查询需求。","vectorScore":0.67825323},{"relatedText":"低成本:高压缩比,数据冷热分离,支持HDD/OSS存储。\n\t弹性伸缩:存储计算分离架构,支持独立伸缩,自动化扩容。\n\t使用灵活:动态列,自由增减特征/标签属性;TTL,数据自动过期;多版本。\n\t低延迟:单个毫秒响应,支持双集群请求并发加速。\n\t数据通道:通过LTS(原BDS)构建Lindorm与异构计算系统的高效、易用的数据链路。\n\t高可用:主备双活容灾,请求自动容错,满足99.\n\t95% | | SLA。","vectorScore":0.61903703}] | +----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
原理解析
上述流程中,CREATE MODEL创建检索问答模型是关键步骤,在背后,Lindorm AI引擎会从宽表引擎中拉取对应的文档数据进行全量的切片及Embedding 向量化,并将结果以中间表的形式保存与宽表引擎中,同时构建对应的向量索引。这里切片和向量化都是在推理引擎上利用AI模型来完成(借助Lindorm AI引擎从模型平台导入模型的能力),默认分别使用了Bert语义分割模型以及text2vec-base-chinese模型(未来可通过参数形式开放自由选择)。此外,这里还利用了Lindorm流引擎的能力来进行文档增量数据订阅及对应的处理,免去应用层需要处理文档更新的问题。在问答的流程中,自动完成包括对问题向量化、向量检索出相关文档切片并进行Prompt重新组织的步骤,通过API的方式和背后的LLM进行交互。这里除了支持公共的LLM(如通义千问外),还支持开源LLM在Lindorm内的私有部署(如ChatGLM-6B等),解决您对于数据安全上的顾虑。
- 本页导读 (1)